A new comprehensive analysis from Stanford University challenges long-held assumptions about global artificial intelligence leadership. The 2026 AI Index Report, a 423-page annual assessment, indicates that the United States no longer maintains a definitive, durable lead over China in core AI model performance.
This finding is among several significant insights in the report from Stanford’s Institute for Human-Centered Artificial Intelligence. The study tracks research output, investment, public sentiment, and the critical field of responsible AI development.
The Shifting Landscape of AI Capability
The data shows the performance gap between top U.S. and Chinese AI models has effectively closed. Since early 2025, models from the two nations have traded the top position multiple times.
In February 2025, China’s DeepSeek-R1 briefly matched the leading U.S. model. As of March 2026, the top model from U.S. firm Anthropic leads by a narrow margin of just 2.7 percent.
The United States still produced more top-tier AI models in 2025, with 50 compared to China’s 30. It also retains an advantage in higher-impact patents. However, China now leads in overall publication volume, citation share, and total patent grants.
China’s share of the top 100 most-cited AI research papers grew from 33 in 2021 to 41 in 2024. Notably, South Korea leads the world in AI patents per capita.
The report also highlights a structural vulnerability in the AI supply chain. While the U.S. hosts over 5,400 data centers, a single company, Taiwan Semiconductor Manufacturing Company (TSMC), fabricates nearly every leading AI chip used within them.
A Growing Chasm in AI Safety Evaluation
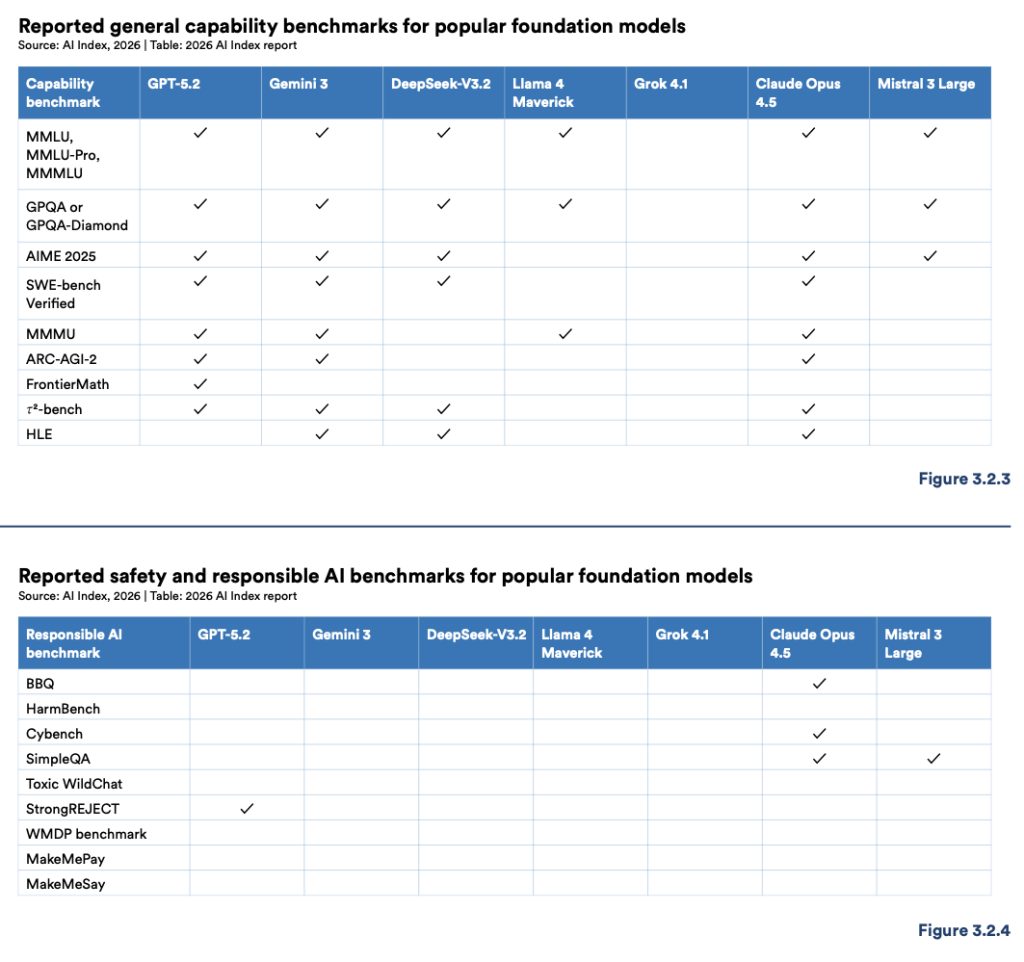
While the capability gap has narrowed, the report reveals a widening and more concerning divide in responsible AI practices. The rigor of safety evaluation and benchmarking is not keeping pace with rapid advances in model power.
The report’s benchmark table for safety and responsible AI shows most entries are blank. Only one model, Claude Opus 4.5, reports results on more than two of the tracked responsible AI benchmarks. Only GPT-5.2 reports results for the StrongREJECT safety benchmark.
Across benchmarks measuring fairness, security, and respect for human agency, the majority of leading frontier AI models report no data. This contrasts sharply with capability benchmarks, which are reported consistently.
The report clarifies this does not mean developers are doing no internal safety work. It acknowledges red-teaming and alignment testing occur but notes these efforts are rarely disclosed using a common, externally comparable set of benchmarks. This lack of standardization makes external comparison of AI safety effectively impossible.
Documented AI incidents rose to 362 in 2025, up from 233 in 2024, according to the AI Incident Database. Another tracking system from the OECD recorded a peak of 435 monthly incidents in January 2026.
Organizational and Public Response
Organizational governance is struggling to match the pace of incident growth. A survey conducted for the Index found the share of organizations rating their AI incident response as excellent dropped from 28 percent in 2024 to 18 percent in 2025.
Those reporting good responses also fell, from 39 percent to 24 percent. Meanwhile, the share of organizations experiencing three to five incidents rose from 30 percent to 50 percent.
The report identifies a fundamental challenge in improving responsible AI: gains in one dimension often reduce performance in another. Improving safety can degrade accuracy, while enhancing privacy may reduce fairness. No established framework exists for managing these trade-offs.
Public sentiment reflects this complex reality. Globally, 59 percent of people surveyed believe AI’s benefits outweigh its drawbacks, up from 55 percent in 2024. Simultaneously, 52 percent say AI products make them nervous, a figure that increased two percentage points in one year.
This suggests a public that is adopting AI more widely while growing more uncertain about its long-term trajectory.
Looking ahead, the pressure to establish universal safety benchmarks and transparent reporting standards will intensify. Industry consortia and regulatory bodies are expected to propose formal evaluation frameworks within the next 12 to 18 months. The development of standardized datasets for tracking progress in fairness and explainability is also a stated priority for leading research institutes.






